
Observability & OpenTelemetry im .NET-Umfeld
Observability ermöglicht es, den Zustand komplexer Systeme anhand ihrer Ausgaben zu verstehen. Dies ist für den Betrieb und die Fehleranalyse insbesondere in verteilten Systemen unverzichtbar.
Da wir den Anspruch auf qualitativ hochwertigen Code haben, welcher wartbar und erweiterbar sein soll, ist Observability bei uns ein fixer Bestandteil. Wir setzen dabei auf OpenTelemetry als Standard.
In diesem Blogbeitrag geben wir einen kompakten Überblick über Observability im .NET Umfeld und gehen auf unsere Erfahrungen ein.
Die 3 Säulen der Observability
Durch die Kombination aller drei Observability Säulen: Metriken, Traces und Logs erhalten Entwicklungs- und Betriebsteams eine umfassende und detaillierte Einsicht in das Verhalten komplexer Systeme.
Gemeinsam ermöglichen sie eine schnellere Problemerkennung und -lösung, stellen ergänzende Werkzeuge zur Verfügung, verbessern die Systemleistung und schaffen die Grundlage für Full Stack Observability. Um vom Frontend, über das Backend bis zur Infrastruktur, alles im Blick zu haben.
Metriken: das «Was» im System
Metriken liefern quantitative Messwerte, die das Verhalten eines Systems über die Zeit abbilden.
Sie werden häufig aggregiert, um eine übersichtliche Darstellung in Dashboards und Visualisierungen wie Zeitreihendiagrammen zu ermöglichen. Metriken sind essenziell für die Einrichtung von Alarmierungen und bieten wertvolle Einblicke in Systemleistung, Ressourcennutzung und den allgemeinen Gesundheitszustand.
Ihr Hauptzweck besteht darin festzustellen «was» im System vorliegt (Normalbetrieb, Einschränkung, Fehler).
Typische Beispiele für Metriken sind:
- Host-Metriken: Speicherverbrauch, Festplattenauslastung, CPU-Nutzung
- Netzwerkmetriken: Betriebszeit, Latenz, Durchsatz
- Anwendungsmetriken: Antwortzeiten, Anfrage- und Fehlerraten
- Serverpool-Metriken: Anzahl der Gesamt- und aktiven Instanzen
- Metriken externer Abhängigkeiten: Verfügbarkeit, Servicestatus
Praxis-Tipp:
Für .NET empfehlen wir die Integration von OpenTelemetry Metrics oder Prometheus.NET, kombiniert mit Grafana für Visualisierungen.
Logs: das «Warum» hinter Ereignissen
Logs sind unveränderliche, detaillierte Aufzeichnungen einzelner Ereignisse und liefern den Kontext für die Ursachenanalyse. Protokolle enthalten typischerweise:
- Zeitstempel
- Transaktions-IDs
- IP- und Benutzer-IDs
- Ereignisdetails und Ablaufinformationen
- Fehlermeldungen
- Verbindungsversuche
- Konfigurationsänderungen
Sie erfassen wichtige Ereignisse, Fehler und Warnungen und ermöglichen es, das Systemverhalten über die Zeit nachzuvollziehen.
Ein weiterer wichtiger Aspekt der Logs sind die Log-Levels. Damit lassen sich Ereignisse in bestimmten Gruppen zusammenfassen. Gemäss unserer Erfahrung haben sich folgende Log-Levels bewährt:
- Debug: Entwickler-Infos
- Info: Normalbetrieb
- Warning: Auffälligkeiten
- Error: Fehler
Durch die Korrelation mit Traces (z. B. über Trace ID und Span ID) lassen sich Abläufe noch präziser analysieren.
Praxis-Tipp:
Nutze strukturierte Logs (z. B. JSON) und bewährte Frameworks wie Serilog oder NLog. So lassen sich Logs nicht nur flexibel auswerten, sondern auch gezielt nach Feldern filtern, ideal für zentrale Log-Management-Systeme und gezielte Analysen.
Traces: das «Wo und Wie» im System
Traces zeichnen den Ablauf einer Anfrage über mehrere Komponenten eines verteilten Systems auf. Sie helfen dabei Engpässe, Latenzen und Fehlerquellen zu identifizieren, indem nachvollziehbar wird, was vor und nach dem Ereignis passierte.
Traces ermöglichen:
- Die Analyse der Dauer von Netzwerkoperationen
- Die Nachverfolgung des Datenflusses durch die Systemarchitektur
- Die Rekonstruktion der Reihenfolge, in der Dienste durchlaufen werden
- Die Identifikation von Fehlerursachen, Engpässen und Latenzproblemen
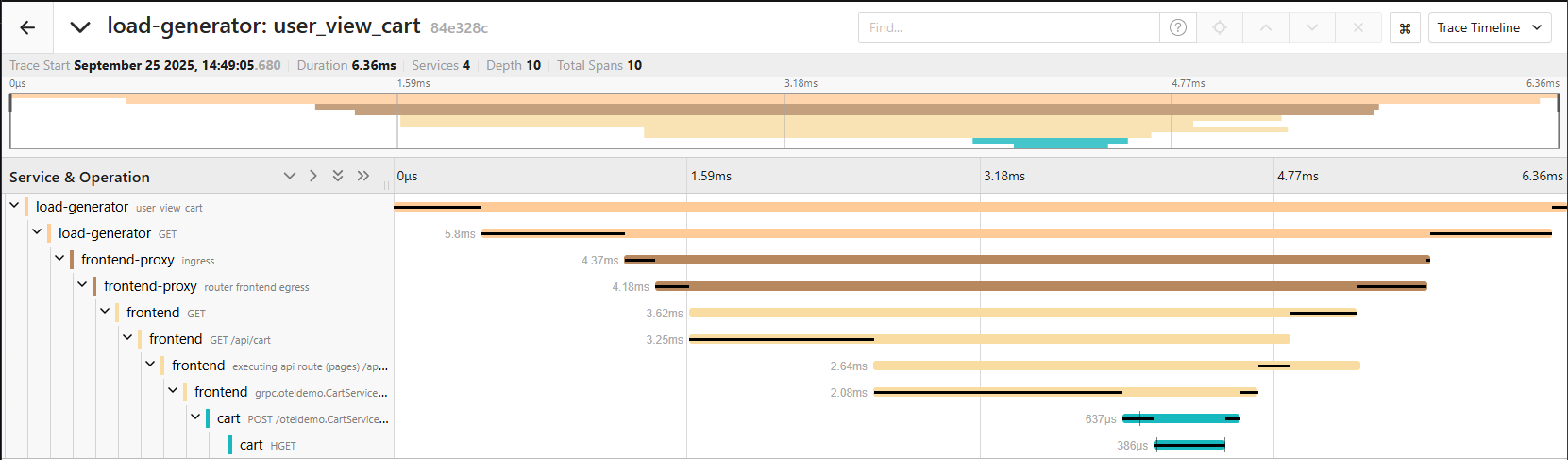
Sie kombinieren Aspekte von Metriken und Logs, indem sie Kontextinformationen über den Lebenszyklus einer Anfrage liefern. Dabei wird der gesamte Weg einer Anfrage sichtbar gemacht – inklusive aller beteiligten Komponenten und deren jeweiliger Bearbeitungszeit.
Traces sind besonders hilfreich für DevOps und Entwicklungsteams, da sie komplexe Abläufe transparent machen und die Ursachenanalyse bei Systemstörungen erleichtern.
Praxis-Tipp:
Für verteilte Systeme ist OpenTelemetry Tracing mit Exportern wie Jaeger oder Zipkin Standard. Auto-Instrumentierung deckt teilweise Standardfälle ab, aber sobald du individuelle Anforderungen hast, etwa Bezug zur Business-Logik, spezielle Messaging-Systeme oder zusätzliche Kontextinformationen, reicht sie nicht mehr aus.
Plane dann ausreichend Zeit für manuelle Instrumentierung und saubere Kontextpropagation ein.
Das ist kein „Plug & Play“, sondern erfordert gezielte Implementierung und Coding.
Umsetzungsaufwand und Nutzen Vergleich
| Säule | Implementierungsaufwand | Nutzen |
|---|---|---|
| Logs | Gering | Ursachenanalyse, Fehlerkontext |
| Metriken | Mittel | Performance Monitoring, Alarmierungen |
| Traces | Hoch | End to End Transparenz, Engpassanalyse |
- Logs und Metriken sind die «Low-hanging Fruits» der Observability, da sie mit geringen Aufwand implementiert sind und bereits die wichtigsten Punkte wie die Identifikation von Anomalien, Fehlern und die Überwachung von Performance Indikatoren erlauben.
- Traces sind für verteilte Systeme und das Debugging extrem hilfreich, jedoch auch deutlich aufwändiger in der Implementation
OpenTelemetry
Im ersten Teil wurden die Grundlagen zu den drei Säulen der Observability vorgestellt. Nachfolgend wird nun die Umsetzung mit OpenTelemetry als de-facto-Standard für Observability erläutert.
OpenTelemetry ist ein leistungsfähiges Open-Source-Framework, das eine einheitliche und standardisierte Methode zur Erfassung, Verarbeitung und Weiterleitung von Telemetriedaten wie Metriken, Logs und Traces bietet. Nachfolgend die wichtigsten Vorteile:
- Vendor-Neutralität
Es ist unabhängig von kommerziellen Anbietern und unterstützt eine Vielzahl von Programmiersprachen, was Entwickler maximale Flexibilität bei der Integration in bestehende Systemlandschaften bietet. Das bedeutet: Egal ob du Jaeger, Prometheus oder Grafana nutzt, OpenTelemetry integriert sich nahtlos
- Standardisierung über Sprachen hinweg
OpenTelemetry stellt stabile APIs und SDKs für viele gängige Programmiersprachen bereit und sorgt so für konsistente Implementierungen über unterschiedliche Technologie-Stacks hinweg. Für .NET sind alle drei Bereiche stabil und ist damit bestens für die produktive Implementation geeignet.
| Language | Traces | Metrics | Logs |
|---|---|---|---|
| C++ | Stable | Stable | Stable |
| C#/.Net | Stable | Stable | Stable |
| Erlang/Elixir | Stable | Development | Development |
| Go | Stable | Stable | Beta |
| Java | Stable | Stable | Stable |
| JavaScript | Stable | Stable | Development |
| PHP | Stable | Stable | Stable |
| Python | Stable | Stable | Development |
| Ruby | Stable | Development | Development |
| Rust | Beta | Beta | Beta |
| Swift | Stable | Development | Development |
- Flexibilität und Erweiterbarkeit
OpenTelemetry unterstützt verschiedene Datenformate und Backend-Systeme wie Prometheus, Jaeger, Zipkin, Grafana oder Elastic, wodurch sich Telemetriedaten problemlos in bestehende Monitoring- und Analyseplattformen integrieren lassen Dank der modularen Architektur lässt sich OpenTelemetry einfach erweitern, etwa durch eigene Instrumentierungen oder Exporter. Ein Wechsel des Backends ist ebenfalls unkompliziert, da die Instrumentierung unverändert bleibt und nur die Exporter- oder Collector-Konfiguration angepasst werden muss.
OTELCollector
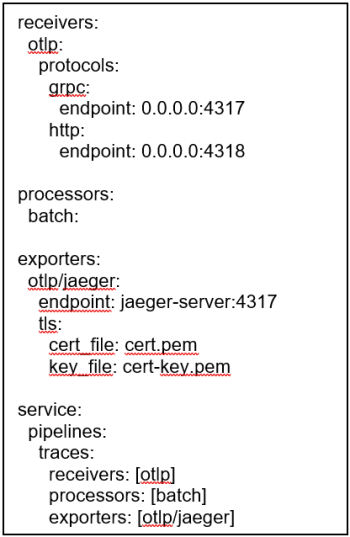
Der OpenTelemetry Collector ist eine zentrale Komponente. Durch den OTEL Collector werden die Telemetriedaten wie Metriken, Logs und Traces gesammelt, verarbeitet und weitergeleitet. Er läuft als eigenständiger Dienst und ermöglicht die Trennung von Instrumentierung und Backend, wodurch Flexibilität und Skalierbarkeit erhöht werden.
Der Kollektor lässt sich je nach Bedarf konfigurieren, die Konfiguration auf der linken Seite erstellt eine Trace Pipeline, die Traces via otlp empfängt, via batch verarbeitet und mit TLS an einen Jaeger Server exportiert
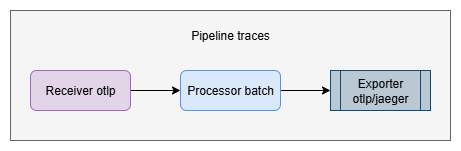
- Pipeline
Eine Pipeline im Collector beschreibt den Weg, den Telemetriedaten durchlaufen – vom Empfang über die Verarbeitung bis zum Export. Sie besteht aus mehreren modularen Komponenten (Receiver, Processor, Exporter), die konfigurierbar sind und unterschiedliche Aufgaben übernehmen.
- Receivers
Receivers sind die Eingangspunkte der Pipeline. Sie nehmen Telemetriedaten aus verschiedenen Quellen entgegen z. B. von Anwendungen, Agenten oder anderen Kollektoren und leiten die Daten an die Pipeline weiter. Beispiele sind OTLP, Prometheus oder Jaeger Receiver.
- Processor
Processor-Komponenten verarbeiten die empfangenen Daten innerhalb der Pipeline. Sie können Daten anreichern, filtern, gruppieren oder transformieren. Typische Aufgaben sind z. B. das Entfernen sensibler Informationen oder das Hinzufügen von Attributen.
- Exporter
Exporter sind die Ausgangspunkte der Pipeline. Sie senden die verarbeiteten Telemetriedaten an ein Zielsystem wie ein Observability-Backend (z. B. Grafana, Jaeger, Datadog oder Prometheus), wo die Daten gespeichert und analysiert werden können.
Fazit
- Observability ist unverzichtbar für den Betrieb verteilter Systeme, den ohne ist man «blind».
- Starte klein und wachse mit der Komplexität: Beginne mit Logs und Metriken und ergänze Traces wenn nötig. Hierbei ist auch die Relevanz der Daten zu beachten. Mehr Daten bedeutet nicht automatisch mehr Insights. Die Daten müssen bewusst ausgewählt und die nachfolgenden Analysen dazu ausgelegt sein.
- Strukturierte Logs (z. B. im JSON-Format) sind eine wichtige Grundlage für effiziente Auswertung und erleichtern automatisierte Verarbeitung, etwa für Filterung, Alerting oder Analyse in zentralen Log-Systemen.
- OpenTelemetry erleichtert die Umsetzung durch Standardisierung erheblich und dies ohne die Flexibilität einzuschränken (Vendor-Neutralität).
- In Kombination mit dem OTLP Collector lässt sich die Instrumentierung vom Backend trennen und es resultiert eine skalierbare und zukunftssichere Observability Architektur.

Patrick Heiniger
Dipl. Techniker HF in Informatik / NDS Software Engineering SWS
Software Engineer
Über den Autor
Patrick Heiniger arbeitet seit über 19 Jahren als Software Engineer bei der CSA.
Er unterstützt Kunden im Application Bereich bei Architektur und Entwicklung im Web und Cloud Projekten oder generell im .Net Umfeld. Sein Interesse an neuen Technologien und seine Motivation sich stetig weiterzubilden haben ihm ein Breites Einsatzgebiet eröffnet.